Ted Dunning and I have worked on a tutorial that explains how to write your first Kafka application. In this tutorial you will learn how to:
- Install and start Kafka
- Create and Run a producer and a consumer
You can find the tutorial on the MapR blog:
Ted Dunning and I have worked on a tutorial that explains how to write your first Kafka application. In this tutorial you will learn how to:
You can find the tutorial on the MapR blog:
Apache Drill has a hidden gem: an easy to use REST interface. This API can be used to Query, Profile and Configure Drill engine.
In this blog post I will explain how to use Drill REST API to create ascii dashboards using Blessed Contrib.
The ASCII Dashboard looks like
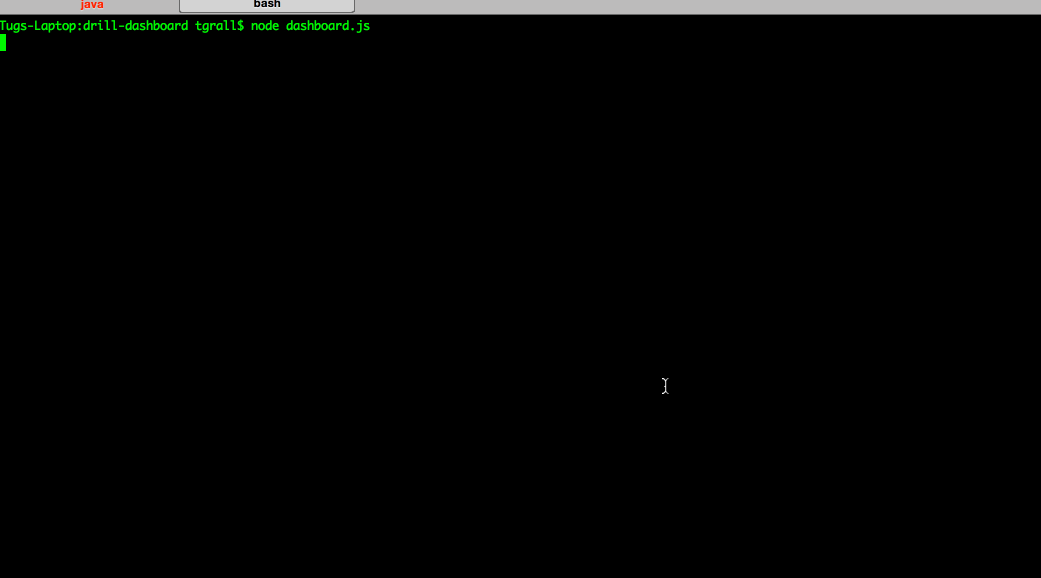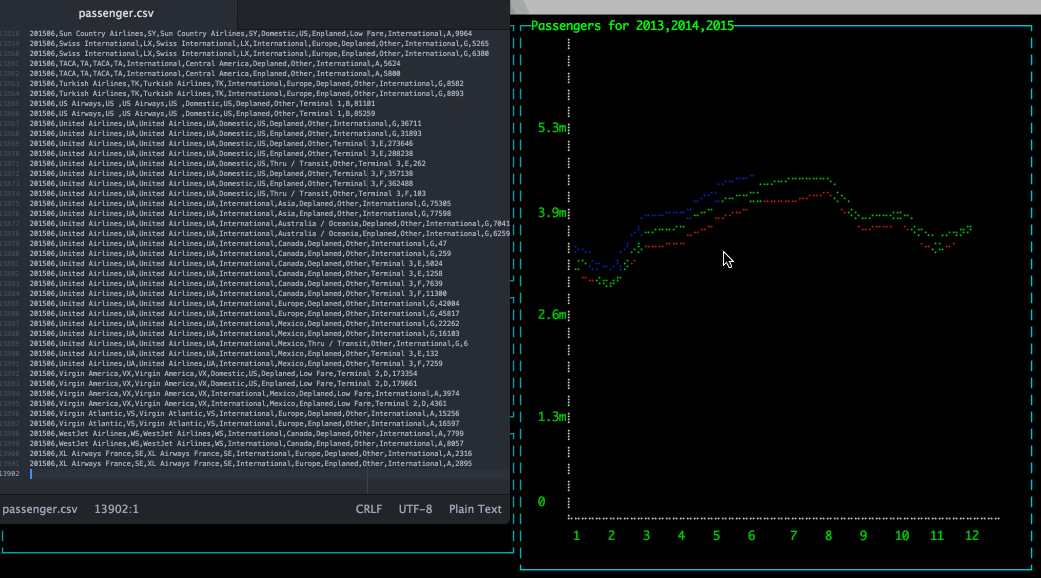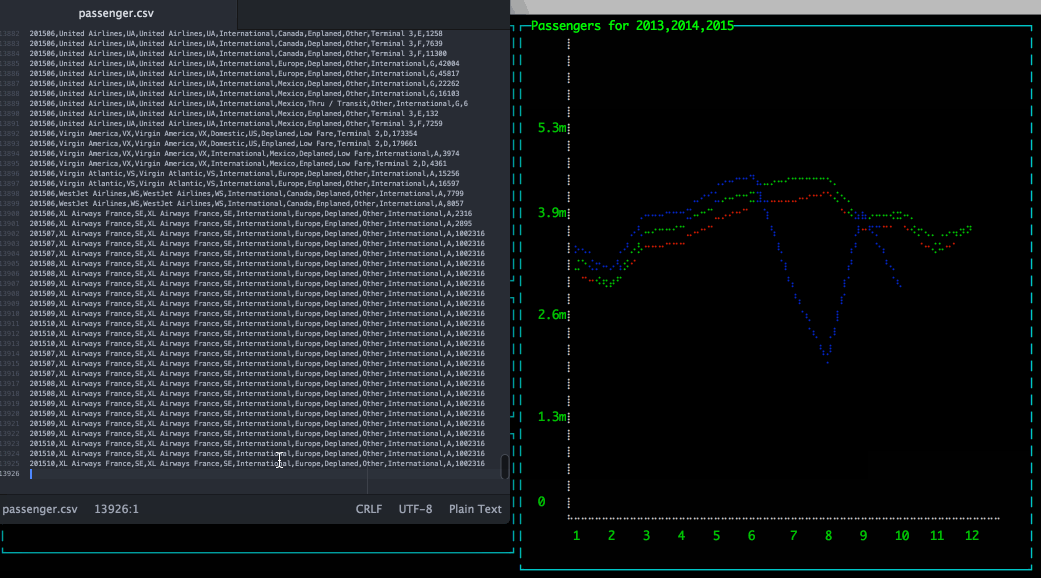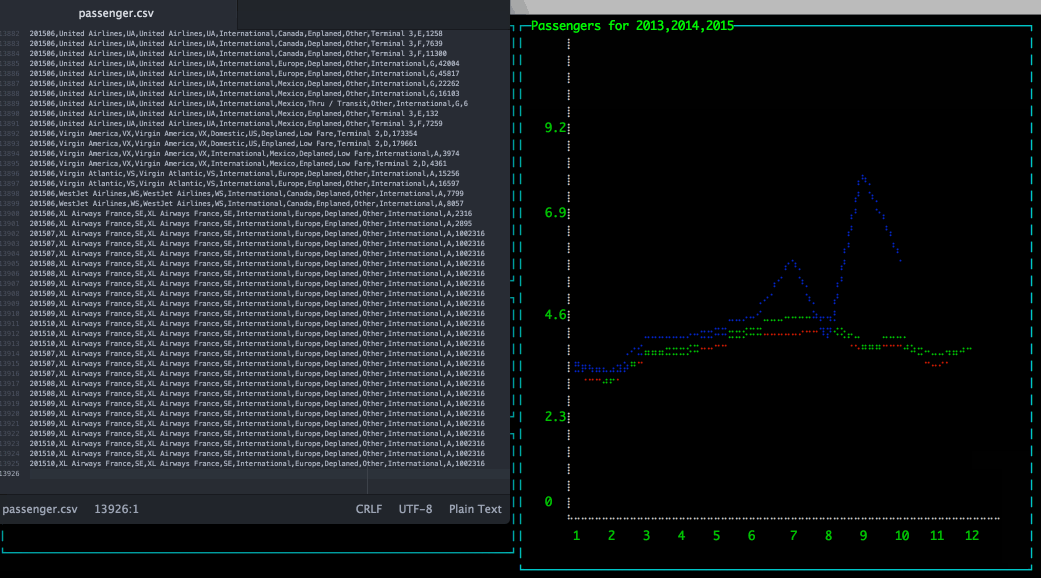
A very common use case when working with Hadoop is to store and query simple files (CSV, TSV, ...); then to get better performance and efficient storage convert these files into more efficient format, for example Apache Parquet.
Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem. Apache Parquet has the following characteristics:
Let's take a concrete example, you can find many interesting Open Data sources that distribute data as CSV files- or equivalent format-. So you can store them into your distributed file system and use them in your applications/jobs/analytics queries. This is not the most efficient way especially when we know that these data won't move that often. So instead of simply storing the CSV let's copy this information into Parquet.
You can use code to achieve this, as you can see in the ConvertUtils sample/test class. You can use a simpler way with Apache Drill. Drill allows you save the result of a query as Parquet files.
The following steps will show you how to do convert a simple CSV into a Parquet file using Drill.
Apache Drill allows users to explore any type of data using ANSI SQL. This is great, but Drill goes even further than that and allows you to create custom functions to extend the query engine. These custom functions have all the performance of any of the Drill primitive operations, but allowing that performance makes writing these functions a little trickier than you might expect.
In this article, I'll explain step by step how to create and deploy a new function using a very basic example. Note that you can find lot of information about Drill Custom Functions in the documentation.
Let's create a new function that allows you to mask some characters in a string, and let's make it very simple. The new function will allow user to hide x number of characters from the start and replace then by any characters of their choice. This will look like:
MASK( 'PASSWORD' , '#' , 4 ) => ####WORD
You can find the full project in the following Github Repository.
As mentioned before, we could imagine many advanced features to this, but my goal is to focus on the steps to write a custom function, not so much on what the function does.
For this you will need:
The following Drill dependency should be added to your maven project
<dependency>
<groupId>org.apache.drill.exec</groupId>
<artifactId>drill-java-exec</artifactId>
<version>1.1.0</version>
</dependency>
The Mask function is an implementation of the DrillSimpleFunc.
Developers can create 2 types of custom functions:
Simple functions are often referred to as UDF's which stands for user defined function. Aggregation functions are referred to as UDAF which stands for user defined aggregation function.
In this example, we just need to transform the value of a column on each row, so a simple function is enough.
The first step is to implement the DrillSimpleFunc interface.
package org.apache.drill.contrib.function;
import org.apache.drill.exec.expr.DrillSimpleFunc;
import org.apache.drill.exec.expr.annotations.FunctionTemplate;
@FunctionTemplate(
name="mask",
scope= FunctionTemplate.FunctionScope.SIMPLE,
nulls = FunctionTemplate.NullHandling.NULL_IF_NULL
)
public class SimpleMaskFunc implements DrillSimpleFunc{
public void setup() {
}
public void eval() {
}
}
The behavior of the function is driven by annotations (line 6-10)
Now we need to implement the logic of the function using setup() and eval() methods.
setup is self-explanatory, and in our case we do not need to setup anything.eval that is the core of the function. As you can see this method does not have any parameter, and return void. So how does it work?In fact the function will be generated dynamically (see DrillSimpleFuncHolder), and the input parameters and output holders are defined using holders by annotations. Let's look into this.
import io.netty.buffer.DrillBuf;
import org.apache.drill.exec.expr.DrillSimpleFunc;
import org.apache.drill.exec.expr.annotations.FunctionTemplate;
import org.apache.drill.exec.expr.annotations.Output;
import org.apache.drill.exec.expr.annotations.Param;
import org.apache.drill.exec.expr.holders.IntHolder;
import org.apache.drill.exec.expr.holders.NullableVarCharHolder;
import org.apache.drill.exec.expr.holders.VarCharHolder;
import javax.inject.Inject;
@FunctionTemplate(
name = "mask",
scope = FunctionTemplate.FunctionScope.SIMPLE,
nulls = FunctionTemplate.NullHandling.NULL_IF_NULL
)
public class SimpleMaskFunc implements DrillSimpleFunc {
@Param
NullableVarCharHolder input;
@Param(constant = true)
VarCharHolder mask;
@Param(constant = true)
IntHolder toReplace;
@Output
VarCharHolder out;
@Inject
DrillBuf buffer;
public void setup() {
}
public void eval() {
}
}
We need to define the parameters of the function. In this case we have 3 parameters, each defined using the @Param annotation. In addition, we also have to define the returned value using the @Output annotation.
The parameters of our mask function are:
The function returns :
For each of these parameters you have to use an holder class. For the String, this is managed by a VarCharHolder or NullableVarCharHolder -lines 21, 24,30- that provides a buffer to manage larger objects in a efficient way. Since we are manipulating a VarChar you also have to inject another buffer that will be used for the output -line 33-. Note that Drill doesn't actually use the Java heap for data being processed in a query but instead keeps this data off the heap and manages the life-cycle for us without using the Java
garbage collector.
We are almost done since we have the proper class, the input/output object, we just need to implement the eval() method itself, and use these objects.
public void eval() {
// get the value and replace with
String maskValue = org.apache.drill.exec.expr.fn.impl.StringFunctionHelpers.getStringFromVarCharHolder(mask);
String stringValue = org.apache.drill.exec.expr.fn.impl.StringFunctionHelpers.toStringFromUTF8(input.start, input.end, input.buffer);
int numberOfCharToReplace = Math.min(toReplace.value, stringValue.length());
// build the mask substring
String maskSubString = com.google.common.base.Strings.repeat(maskValue, numberOfCharToReplace);
String outputValue = (new StringBuilder(maskSubString)).append(stringValue.substring(numberOfCharToReplace)).toString();
// put the output value in the out buffer
out.buffer = buffer;
out.start = 0;
out.end = outputValue.getBytes().length;
buffer.setBytes(0, outputValue.getBytes());
}
The code is quite simple:
This code does, however, look a bit strange to somebody used to reading Java code. This strangeness arises because the final code that is executed in a query will actually be generated on the fly. This allows Drill to leverage Java's just-in-time (JIT) compiler for maximum speed. To make this work, you have to respect some basic rules:
Strings class. (coming from the Google Guava API packaged in Apache Drill)ValueHolders classes, in our case VarCharHolder and IntHolder should be manipulated like structs, so you must call helper methods, for example getStringFromVarCharHolder and toStringFromUTF8. Calling methods like toString will result in very bad problems.Starting in Apache Drill 1.3.x, it is mandatory to specify the package name of your function in the ./resources/drill-module.conf file as follow:
drill {
classpath.scanning {
packages : ${?drill.classpath.scanning.packages} [
org.apache.drill.contrib.function
]
}
}
We are now ready to deploy and test this new function.
Once again since, Drill will generate source, you must prepare your package in a way that classes and sources of the function are present in the classpath. This is different from the way that Java code is normally packaged but is necessary for Drill to be able to do the necessary code generation. Drill uses the compiled code to access the annotations and uses the source code to do code generation.
An easy way to do that is to use maven to build your project, and, in particular, use the maven-source-plugin like this in your pom.xml file:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-source-plugin</artifactId>
<version>2.4</version>
<executions>
<execution>
<id>attach-sources</id>
<phase>package</phase>
<goals>
<goal>jar-no-fork</goal>
</goals>
</execution>
</executions>
</plugin>
Now, when you build using mvn package, Maven will generate 2 jars:
Finally you must add a drill-module.conf file in the resources folder of your project, to tell Drill that your jar contains a custom function. If you have no specific configuration to set for your function you can keep this file empty.
We are all set, you can now package and deploy the new function, just package and copy the Jars into the Drill 3rd party folder; $DRILL_HOME/jars/3rdparty , where $DRILL_HOME being your Drill installation folder.
mvn clean package
cp target/*.jar $DRILL_HOME/jars/3rdparty
Restart drill.
You should now be able to use your function in your queries:
SELECT MASK(first_name, '*' , 3) FIRST , MASK(last_name, '#', 7) LAST FROM cp.`employee.json` LIMIT 5;
+----------+------------+
| FIRST | LAST |
+----------+------------+
| ***ri | ###### |
| ***rick | ####### |
| ***hael | ###### |
| ***a | #######ez |
| ***erta | ####### |
+----------+------------+
In this simple project you have learned how to write, deploy and use a custom Apache Drill Function. You can now extend this to create your own function.
One important thing to remember when extending Apache Drill (using a custom function, storage plugin or format), is that Drill runtime is generating dynamically lot of code. This means you may have to use a very specific pattern when writing and deploying your extensions. With our basic function this meant we had to:
As you know, you have many differences between relational and document databases. The biggest, for the developer, is probably the data model: Row versus Document. This is particularly true when we talk about "relations" versus "embedded documents (or values)". Let's look at some examples, then see what are the various operations provided by MongoDB to help you to deal with this.
Last week at the Paris MUG, I had a quick chat about security and MongoDB, and I have decided to create this post that explains how to configure out of the box security available in MongoDB.
You can find all information about MongoDB Security in following documentation chapter:

In this post, I won't go into the detail about how to deploy your database in a secured environment (DMZ/Network/IP/Location/...)
I will focus on Authentication and Authorization, and provide you the steps to secure the access to your database and data.
I have to mention that by default, when you install and start MongoDB, security is not enabled. Just to make it easier to work with.
The first part of the security is the Authentication, you have multiple choices documented here. Let's focus on "MONGODB-CR" mechanism.
The second part is Authorization to select what a user can do or not once he is connected to the database. The documentation about authorization is available here.
Let's now document how-to:
For each type of users I will show how to grant specific permissions.
Few days ago I have posted a joke on Twitter
Moving my Java from Couchbase to MongoDB pic.twitter.com/Wnn3pXfMGi
— Tugdual Grall (@tgrall) January 26, 2015So I decided to move it from a simple picture to a real project. Let's look at the two phases of this so called project:
Look at this screencast to see it in action:
I have like many of you participated to multiple Hackathons where developers, designer and entrepreneurs are working together to build applications in few hours/days. As you probably know more and more companies are running such events internally, it is the case for example at Facebook, Google, but also ING (bank), AXA (Insurance), and many more.
Last week, I have participated to the first Sage Hackathon!
In case you do not know Sage is a 30+ years old ERP vendor. I have to say that I could not imagine that coming from such company… Let me tell me more about it.
![]()
Last night the Nantes MUG (MongoDB Users Group) had its second event. More than 45 people signed up and joined us at the Epitech school (thanks for this!). We were lucky to have 2 talks from local community members:
In this article we will see how to create a pub/sub application (messaging, chat, notification), and this fully based on MongoDB (without any message broker like RabbitMQ, JMS, ... ).
So, what needs to be done to achieve such thing:
All this is possible with some very cool MongoDB features: capped collections and tailable cursors,