Over the past few months, I have switched most of my development workflows to GitHub Copilot CLI. Whether I'm exploring a codebase, writing code, debugging, or even building a new application, I find myself in GitHub Copilot CLI most of the time. It's fast, it keeps me in the flow, and the agentic capabilities make it incredibly productive.
Many users have asked me how to track context usage in the CLI ?
First of all, you can always use the /context and /usage commands to get a snapshot of your current context window usage.
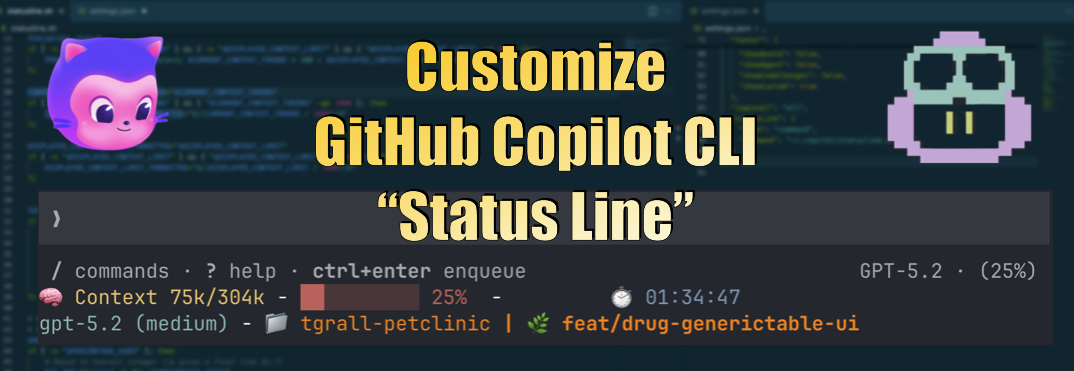
Nevertheless, you can also have a live status line that shows your token consumption and context usage percentage in real time, without needing to type any command, you just need to use the experimental statusLine.command feature to run a custom script to generate the status line content.
As of 1st of May 2026, statusLine.command is an experimental feature and is subject to change. The payload format, configuration keys, and behavior described here may evolve in future releases. I'll do my best to keep this post updated, but always check the official docs for the latest.
This post walks you through setting it up from scratch. I also document the full JSON payload that Copilot sends to your script — I captured it directly from a live session to build the reference table below.
I’ve also published two demonstrations on my YouTube channel: