In my Quarkus application, I encountered a hiccup with the Panache ORM while implementing and testing a REST service. Specifically, I faced a test failure related to the automatic update of a specifications list after deleting an element from the JSON/Entity. In this blog post, I'll walk you through the issue and demonstrate how GitHub Copilot came to the rescue, streamlining the implementation of a solution.
The Challenge:
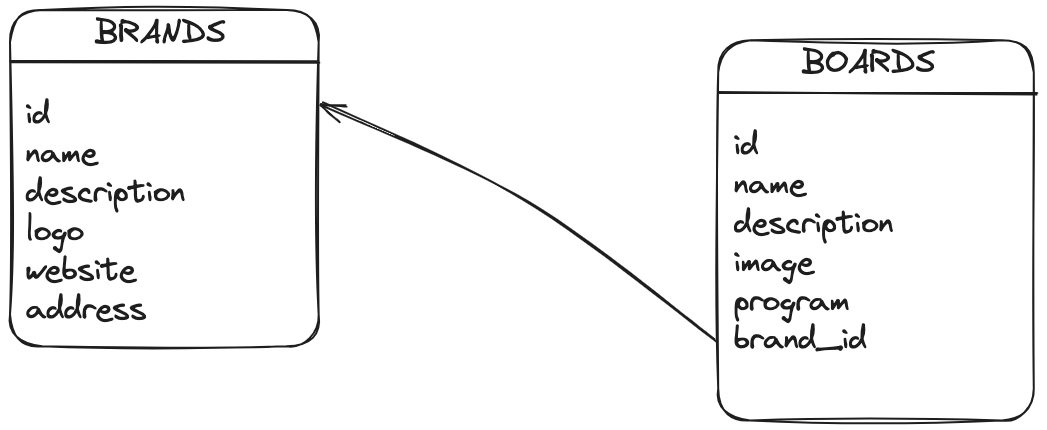
The JSON schema for my REST service looked like this:
{
"id": 1,
"name": "Fanatic Falcon",
"description": "Slalom board",
"specifications" : [
{"id": 10, "name": "Falcom 100", "volume": 100},
{"id": 11, "name": "Falcom 110", "volume": 110},
{"id": 12, "name": "Falcom 120", "volume": 120}
]
```
}
I had a test verifying the number of specifications after the deletion of one of them. However, the Panache ORM didn't automatically update the specifications list after deletion, leading to a failing test.
The Solution:
To address this issue, I needed to implement business logic to delete specifications in the database that were not present in the JSON payload. I documented the logic in a comment and collaborated with GitHub Copilot to generate the code.
Here's a snippet of the code:
...
// if the number of specifications in the existing board is different than the number of specifications in the updated board
// it means that some specifications have been removed, so we need to delete them
// for this we meed to loop on existing specifications and see if they are in the updated board
// if they are not add them to a list of specs to delete
// then use removeAll on existing board specifications
List<BoardSpecification> specsToDelete = new ArrayList<>();
for (BoardSpecification existingSpec : existingBoard.specifications) {
boolean found = false;
for (BoardSpecification spec : board.specifications) {
if (existingSpec.id.equals(spec.id)) {
found = true;
}
}
if (!found) {
specsToDelete.add(existingSpec);
}
}
existingBoard.specifications.removeAll(specsToDelete);
existingBoard.persist();
...
Check out the video below to witness how I leveraged GitHub Copilot to easily implement the business logic.
Once again, GitHub Copilot has proven to be an invaluable coding companion, significantly enhancing my efficiency and helping me overcome challenges in my coding journey. With its assistance, I navigated through the intricacies of the Panache ORM and successfully resolved the test failure, ensuring the seamless functionality of my Quarkus application.